Run AI locally.
No compromises.
Free, open source Mac app for local LLM inference on Apple Silicon. Prefix caching, paged KV cache, continuous batching, and MCP tools — features LM Studio and Ollama don't have.
Everything you need to
run LLMs locally
The fastest MLX inference engine for Apple Silicon. Features that other local AI apps don't offer.
Prefix Cache
Reuse previously computed prefill tokens. Up to 9.7x faster time-to-first-token on cached prompts. Multi-context caching means switching conversations doesn't evict your cache.
Paged KV Cache
Memory-efficient key-value caching with configurable block sizes. Handle longer contexts without running out of unified memory.
Continuous Batching
Serve multiple concurrent requests with intelligent batch scheduling. Up to 256 concurrent sequences.
MCP Tools
Native Model Context Protocol support. Connect models to external tools and APIs for agentic workflows.
OpenAI-Compatible API
Drop-in replacement for OpenAI's chat completions endpoint. Use your existing tools, scripts, and integrations. Streaming, function calling, and structured output all work out of the box.
Built for Apple Silicon
Optimized for unified memory architecture. Run Llama, DeepSeek, Qwen, Gemma, and Mistral locally with maximum throughput.
vMLX vs LM Studio
Real benchmarks on Apple M3 Ultra (256 GB) with Llama 3.2 3B Instruct 4-bit.
Flags:
--continuous-batching --enable-prefix-cache --use-paged-cacheCache: Paged KV cache, multi-context
API: OpenAI /v1/chat/completions (streaming)
Flags: Default settings (auto prefix caching)
Cache: Single-slot (1 active context)
API: OpenAI /v1/chat/completions (streaming)
| Metric | vMLX | LM Studio MLX |
|---|---|---|
| ~2.5K Token Context | ||
| Cold TTFT | 0.50s | — |
| Warm TTFT (cached) | 0.05s | — |
| Cache Speedup | 9.7× | — |
| ~10K Token Context | ||
| Cold TTFT | 0.12s | 6.12s |
| Warm TTFT (cached) | 0.08s | 0.29s |
| Cache Speedup | 1.6× | 21× |
| ~50K Token Context | ||
| Cold TTFT | 0.30s | — |
| Warm TTFT (cached) | 0.22s | — |
| Cache Speedup | 1.4× | — |
| ~100K Token Context | ||
| Cold TTFT | 0.65s | 131.06s |
| Warm TTFT (cached) | 0.45s | 1.14s |
| Cold PP/s | 154,121 | 686 |
| Warm PP/s | 222,462 | 78,635 |
| Architecture | ||
| Cache type | Paged multi-context | Single-slot |
| Multi-conversation | ✓ concurrent caching | ✗ evicts on switch |
| Concurrent sequences | Up to 256 | 1 |
All measurements: TTFT via streaming OpenAI-compatible API. Cold = first request, no cache. Warm = same prefix cached.
vMLX flags: --continuous-batching --enable-prefix-cache --use-paged-cache.
LM Studio: default MLX engine settings.
Model: mlx-community/Llama-3.2-3B-Instruct-4bit.
Hardware: Apple M3 Ultra, 256 GB unified memory. Feb 2026.
Cold = first request (full processing). Warm = same prefix cached. Up to 18.6× faster at 50K tokens.
8-turn coding conversation with 12K system prompt. After turn 1, 99%+ tokens served from cache.
Up and running in seconds
Download vMLX, install the MLX inference backend with one click, pick any model from HuggingFace, and start generating. No cloud, no API keys, no Docker.
- ✓ One-click vLLM-MLX installer
- ✓ Download any MLX-compatible model
- ✓ Automatic server start with smart defaults
- ✓ OpenAI-compatible API on localhost
- ✓ Full chat UI with advanced settings
- ✓ Latest DMG: contains a Developer ID signed and notarized app
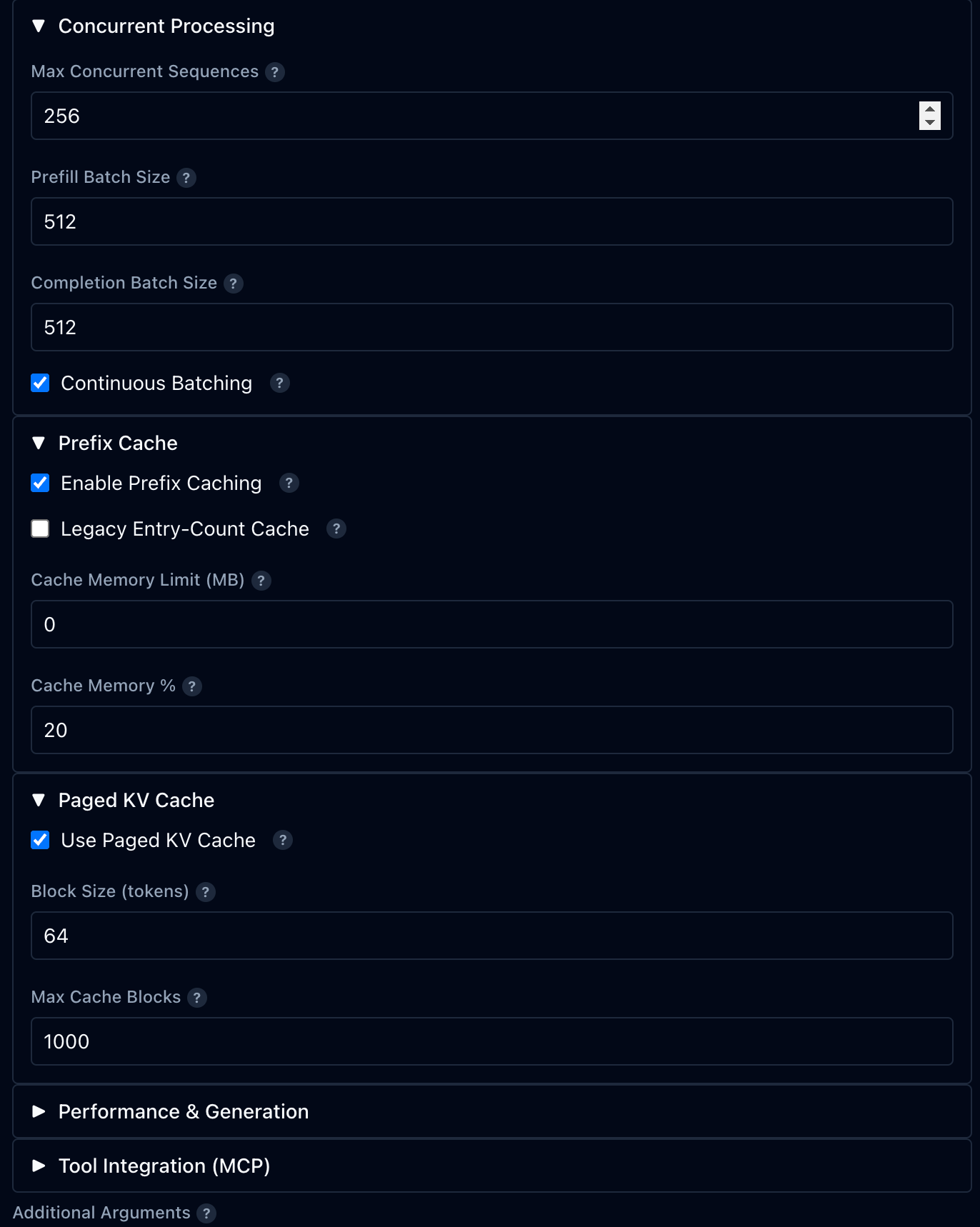
Every parameter
at your fingertips
Fine-tune the MLX inference pipeline. Prefill batch sizes, cache memory, paged KV cache blocks, MCP tool bindings — vMLX exposes all 23 configuration flags.
Questions & answers
What is the best app to run AI locally on a Mac?+
vMLX is the fastest open source Mac app for running LLMs locally on Apple Silicon. Unlike LM Studio or Ollama, vMLX provides prefix caching (up to 9.7x faster time-to-first-token), paged KV cache, continuous batching for up to 256 concurrent sequences, and MCP tool integration. It's free, requires no cloud connection, and works on any M1+ Mac.
How does vMLX compare to LM Studio and Ollama?+
At 100K token context, vMLX achieves 154,121 prompt tokens/sec (cold) vs LM Studio's 686 tok/s. vMLX uses paged multi-context KV caching (concurrent conversations stay cached), while LM Studio uses single-slot caching that evicts on switch. vMLX supports up to 256 concurrent sequences vs 1 for LM Studio. All three offer OpenAI-compatible APIs, but only vMLX exposes all 23 inference parameters.
Can I run DeepSeek, Llama, Qwen, or Gemma locally?+
Yes. vMLX supports any MLX-compatible model from HuggingFace including DeepSeek V3, Llama 3/4, Qwen 2.5/3, Gemma 3, Mistral, Phi, and hundreds more. Models run entirely on your Mac's Apple Silicon GPU. A 16GB Mac handles up to ~20B parameters, while 64GB+ handles 70B+ models.
What is prefix caching and why does it matter?+
Prefix caching stores computed KV states from previous prompt processing. When you send a new message that shares the same system prompt or history, cached tokens are reused instantly. In benchmarks, this reduces TTFT by up to 9.7x on 2.5K context. Critical for multi-turn conversations and agentic workflows.
Do I need internet or API keys?+
No. vMLX runs entirely on your Mac with zero cloud dependency. No API keys, no subscriptions, no rate limits. Your conversations and model weights stay 100% local and private. Internet is only needed to download models initially.
What Mac hardware do I need?+
Any Mac with Apple Silicon (M1, M2, M3, M4, M5 or later). More unified memory = larger models: 8GB handles ~3-7B, 16GB up to ~20B, 32-64GB handles 30-70B, and 128-512GB runs the largest open models at full precision.
Ready to run AI locally?
Free, open source, built for the Apple Silicon Mac you already have.
No cloud. No API keys. No rate limits.